基于大语言模型的大数据分析教学应用探索与实践
计算机学院 李欣
随着大语言模型的兴起,人工智能应用跨入了一个全新的阶段,新技术对现有的知识领域和学习模式带来了新的挑战。在大数据分析领域,可以尝试从辅助学习、辅助分析、辅助科研三个维度进行探索实践。
辅助学习方面,在专业课的教学中,如R语言分析,我们可以鼓励同学们积极融入chatGPT、文心一言等知识增强型大语言模型的使用,如问题的互动检索、程序开发错误分析、探索性新知学习等,引导同学们拥抱新技术,通过对话互动,回答问题,协助创作,高效便捷地帮助同学们获取信息、知识和灵感。如在解决R语言程序开发过程中英文的警告、错误的提示理解和分析,大语言模型便提供了很好的学习实践知识库。

李欣老师教学过程中介绍ChatGPT使用
辅助分析方面,对于数据分析不熟悉的同学,可以使用大语言模型设计大数据分析环节的数据探索过程、预处理函数、构建基本的模型训练、模型评估等方法,为同学们提供解决问题的思路和分析参考,从而使得分析项目有切实可行的切入点。在设计提问时,重点关注Prompt的万能公式三部曲:明确任务和目标、构建提示词或提示语句、选择适当的模型和参数。例如我们需要一个R语言数据缺失值清洗和填充函数。针对这个问题的提问方式,可以设计如下的Prompt模板:"请描述您需要清洗和填充的R语言数据的情况,包括数据集的规模、数据结构、需要清洗和填充的具体内容,类别型和数值型的清洗和填充区别,以及任何其他相关的信息和参数。"
具体的设计内容如下:
请设计一个R语言的缺失值处理函数,实现缺失值的识别和填充。待处理数据集是数据框结构、数据规模至少为1000*5,离散型数据使用众数填充、连续型数据使用均值填充,并以数据框的形式返回处理后的数据。
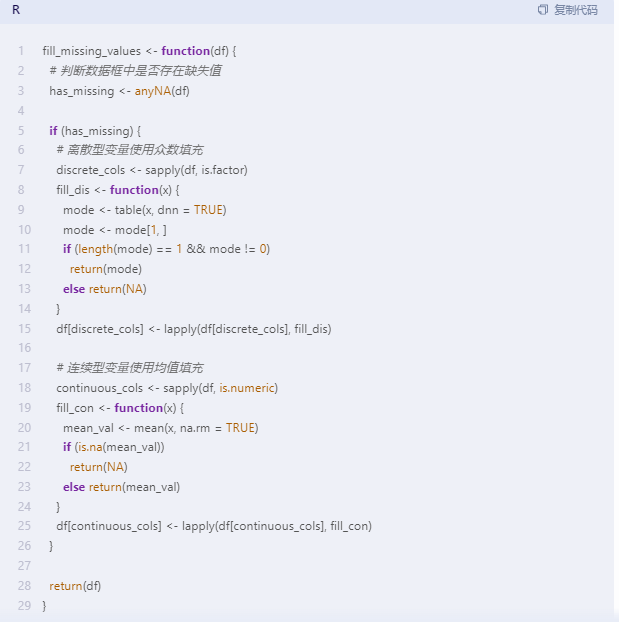
大语言模型生成的R语言预处理框架
大语言模型根据提示词工程,生成了一个基本符合要求的预处理函数,首先检查数据框中是否存在缺失值。如果有,则分别处理离散型和连续型数据。对于离散型数据,我使用众数来填充缺失值;对于连续型数据,我们使用均值来填充缺失值。最后,返回处理后的数据框。注意,这个函数假设数据框中的缺失值表示为NA。如果你的数据框使用不同的方式表示缺失值,你需要相应地修改函数中的代码。
这样的提问方式可以引导回答者详细描述他们的需求,从而更好地理解他们的数据清洗和填充需求。接着可对需求进行详细解析,更准确地为其提供相应解决方案。
辅助科研方面的设想,可采集同学们在使用大语言模型过程中的搜索行为及Prompt问询模板文本,进行NLP自然语言处理分析,探索学生关注的问讯主题词分析,挖掘学生的课程掌握的薄弱环节,洞悉学生自主学习的兴趣点,从而优化老师教学过程中的学生学习画像的构建,帮助老师们更好的结合同学们的学习特点和习惯,因材施教,开展个性化智能化的人才培养。同时该模式具有一定的迁移性,如智慧旅游、出行方式等大数据领域。
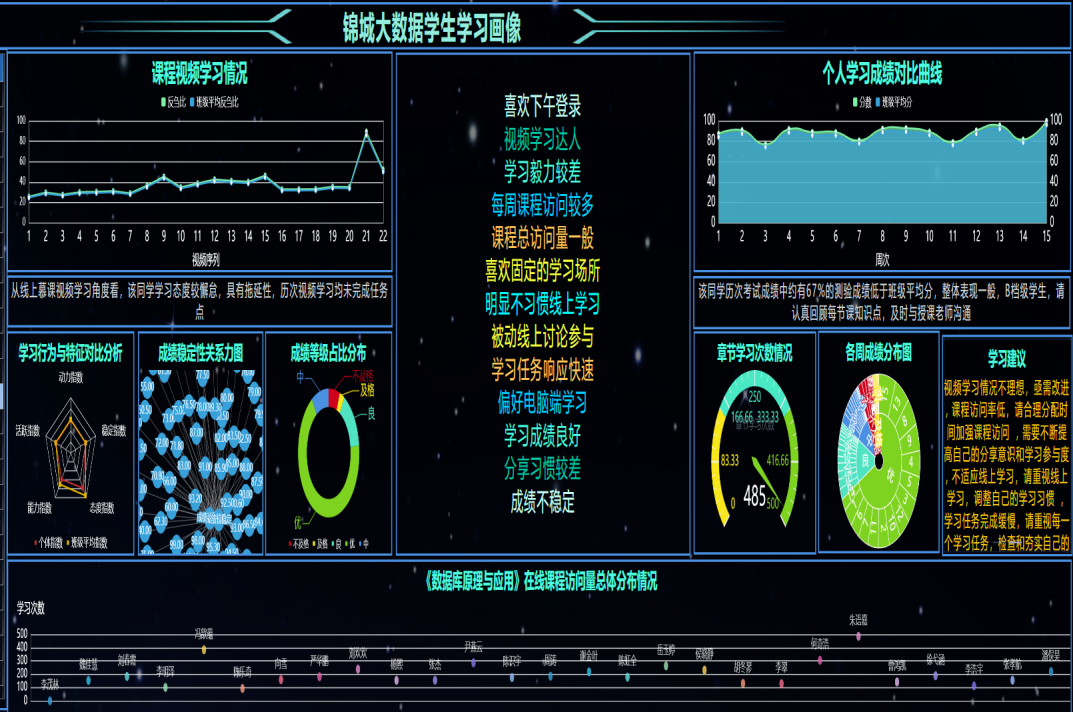
可拓展领域1:学生学习画像
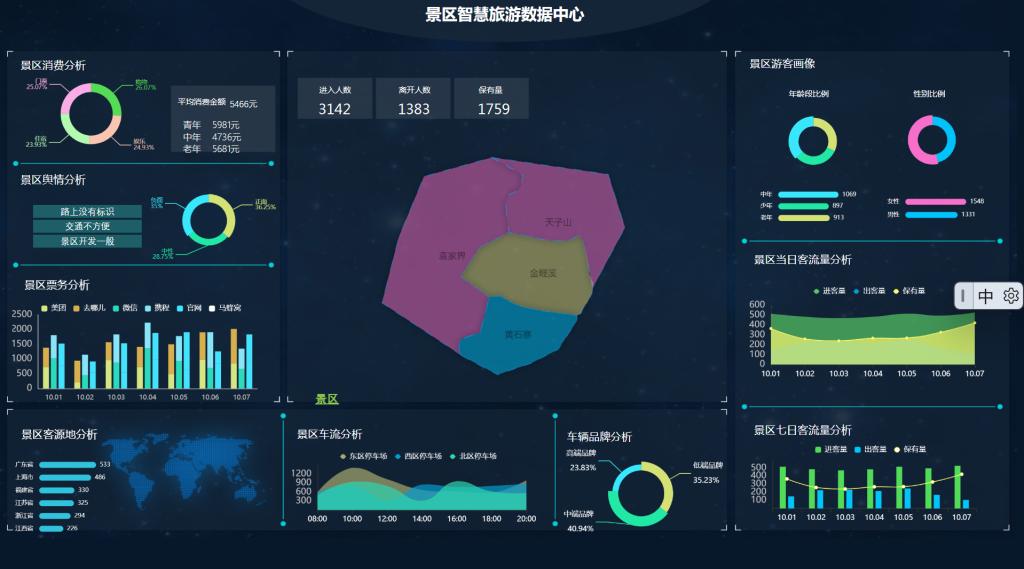
可拓展领域2:大数据智慧旅游

